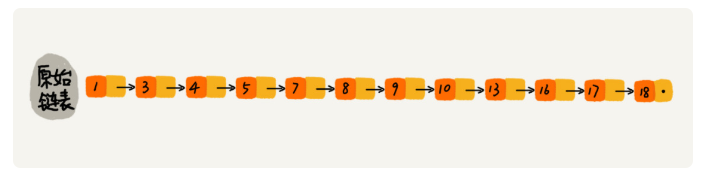
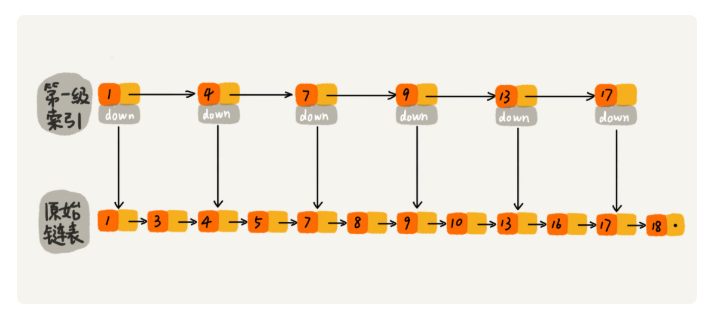
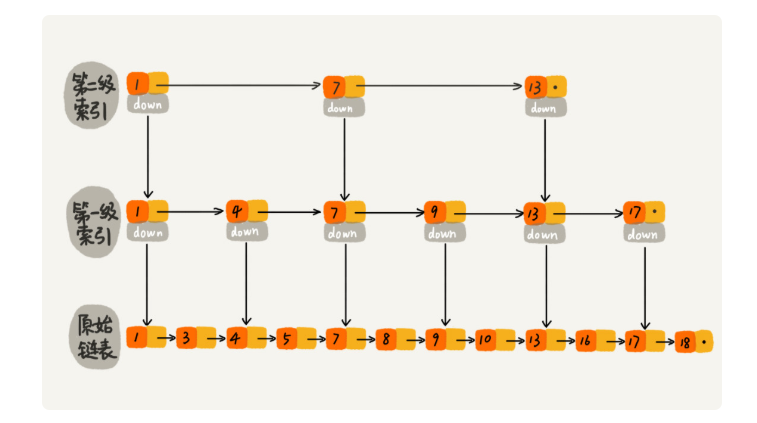
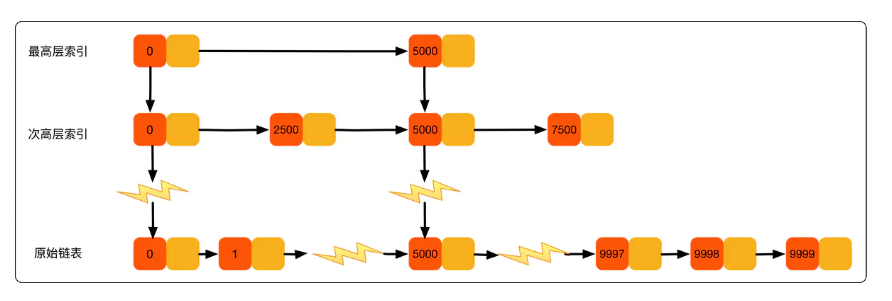
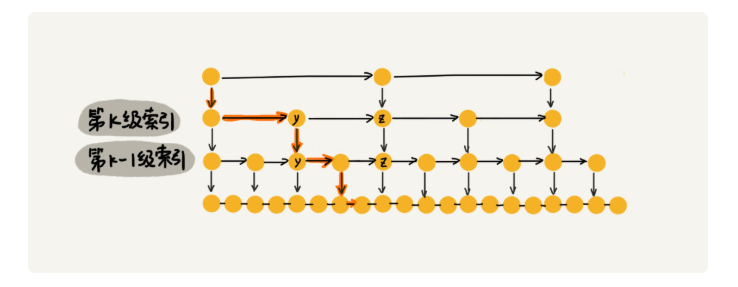
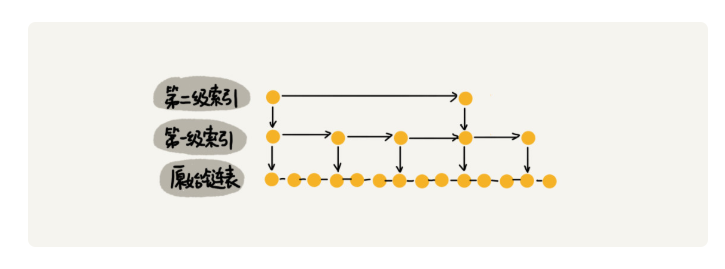
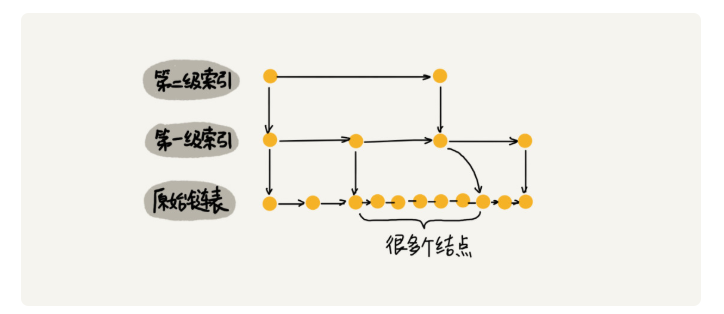
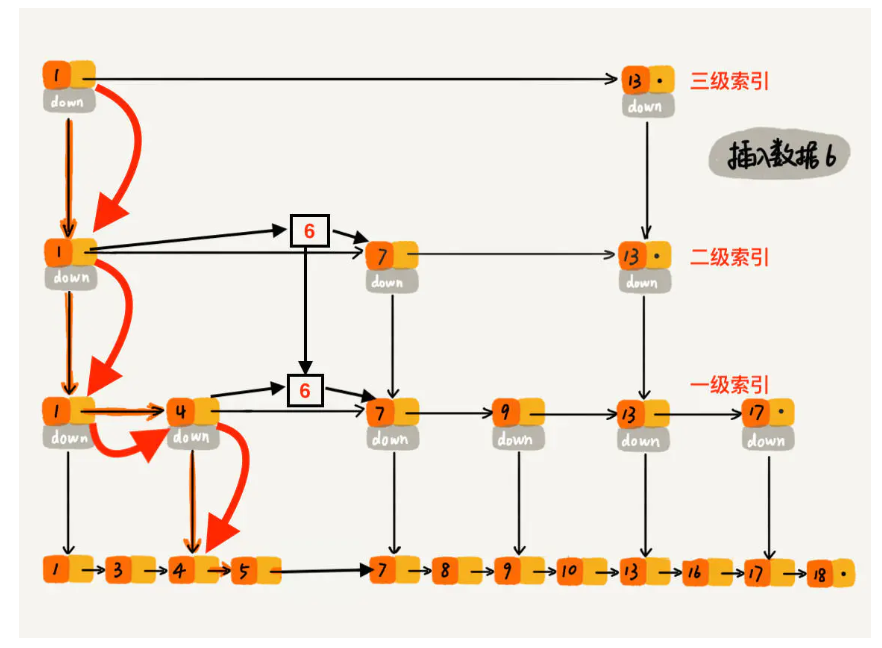
假设索引有 h 级,最高级的索引有 2 个结点。通过上面的公式,我们可以得到 n/(2h)=2,从而求得 h=log2n-1。如果包含原始链表这一层,整个跳表的高度就是 log2n。我们在跳表中查询某个数据的时候,如果每一层都要遍历 m 个结点,那在跳表中查询一个数据的时间复杂度就是 O(m*logn)。
假设我们要查找的数据是 x,在第 k 级索引中,我们遍历到 y 结点之后,发现 x 大于 y,小于后面的结点 z,所以我们通过 y 的 down 指针,从第 k 级索引下降到第 k-1 级索引。在第 k-1 级索引中,y 和 z 之间只有 3 个结点(包含 y 和 z),所以,我们在 K-1 级索引中最多只需要遍历 3 个结点,依次类推,每一级索引都最多只需要遍历 3 个结点,也就是说** m=3。**
classSkipListNode(object): def__init__(self, val, high=1): # 节点存储的值 self.data = val # 节点对应索引层的深度 self.deeps = [None] * high
classSkipList(object): """ An implementation of skip list. The list stores positive integers without duplicates. 跳表的一种实现方法。 跳表中储存的是正整数,并且储存的是不重复的。 Author: Ben """
deffind(self, val): cur = self._head # 从索引的顶层, 逐层定位要查找的值 # 索引层上下是对应的, 下层的起点是上一个索引层中小于插入值的最大值对应的节点 for i in range(self._high - 1, -1, -1): # 同一索引层内, 查找小于插入值的最大值对应的节点 while cur.deeps[i] and cur.deeps[i].data < val: cur = cur.deeps[i]
if cur.deeps[0] and cur.deeps[0].data == val: return cur.deeps[0] returnNone
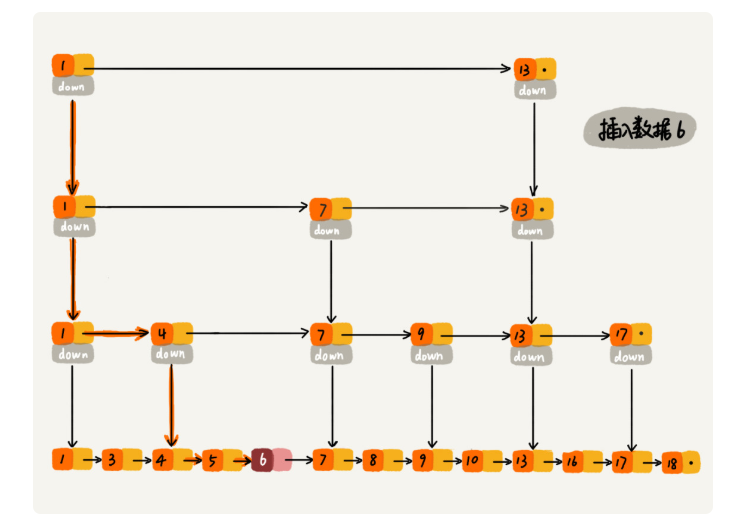
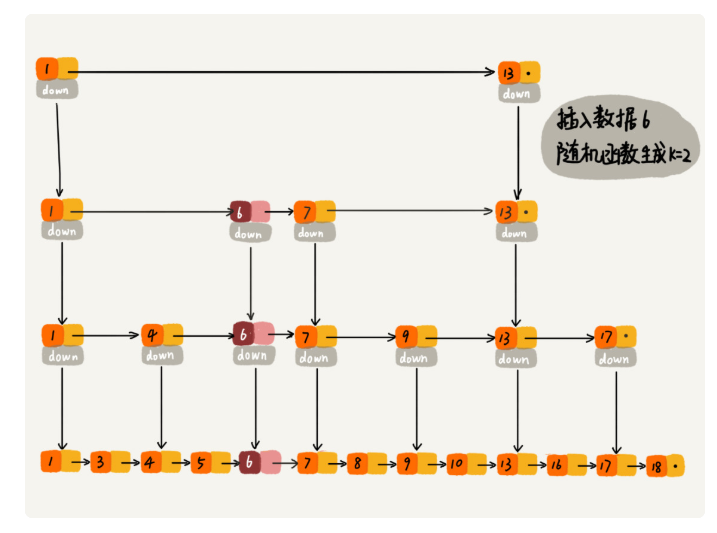
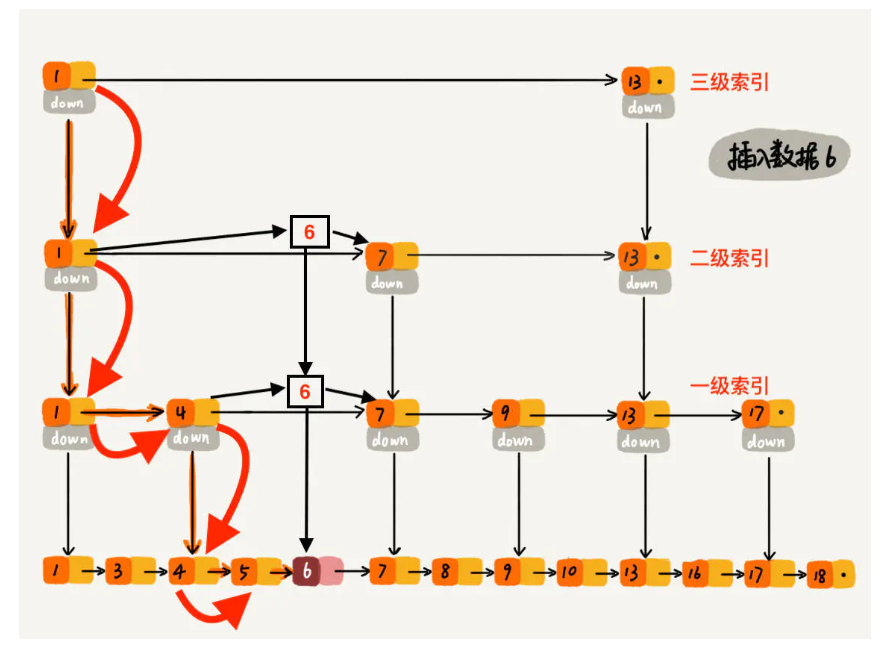
definsert(self, val): ''' 新增时, 通过随机函数获取要更新的索引层数, 要对低于给定高度的索引层添加新结点的指针 ''' high = self.randomLevel() if self._high < high: self._high = high # 申请新结点 newNode = SkipListNode(val, high) # cache用来缓存对应索引层中小于插入值的最大节点 cache = [self._head] * high cur = self._head
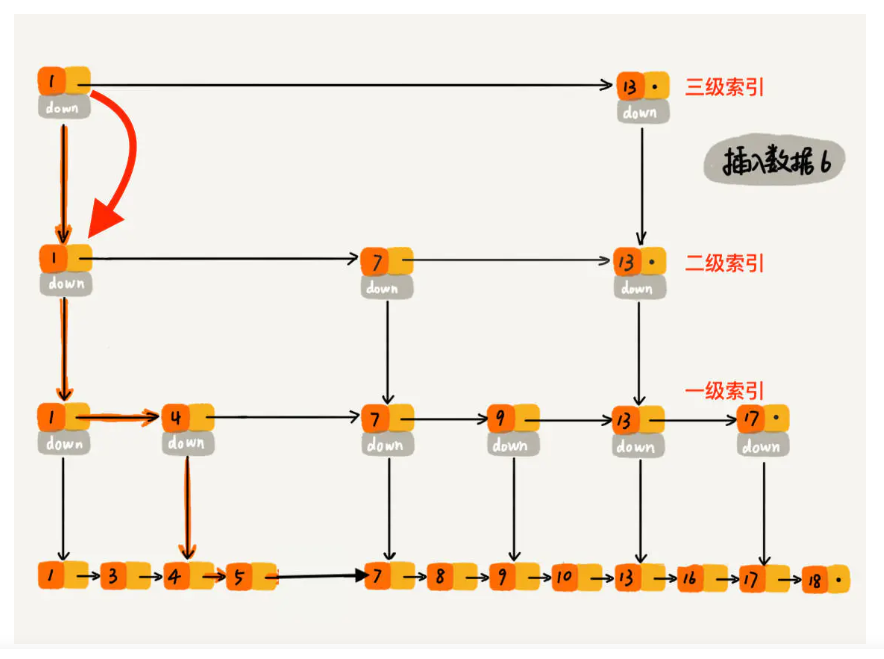
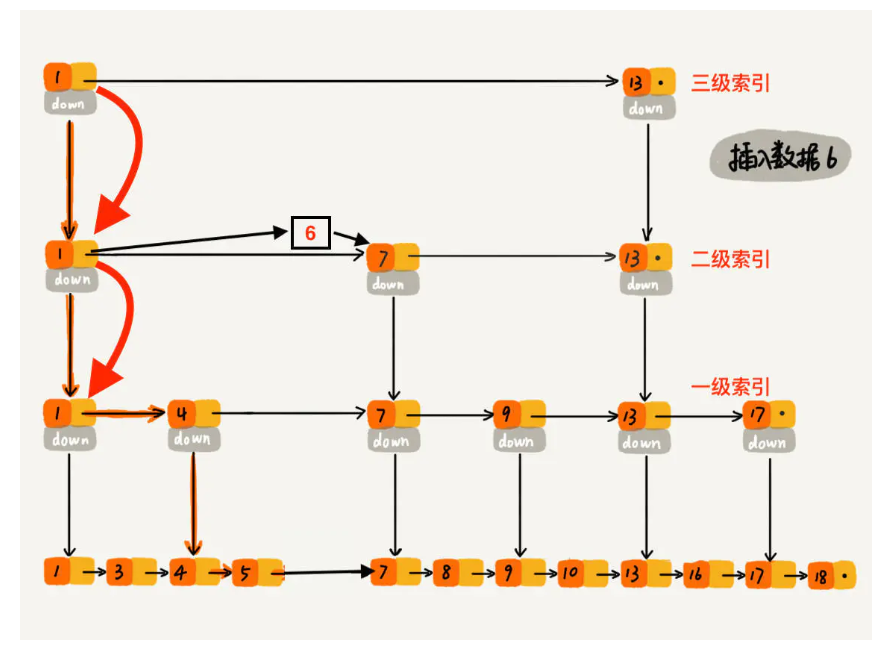
# 在低于随机高度的每一个索引层寻找小于插入值的节点 for i in range(high - 1, -1, -1): # 每个索引层内寻找小于带插入值的节点 # ! 索引层上下是对应的, 下层的起点是上一个索引层中小于插入值的最大值对应的节点 while cur.deeps[i] and cur.deeps[i].data < val: cur = cur.deeps[i] cache[i] = cur
# 在小于高度的每个索引层中插入新结点 for i in range(high): # new.next = prev.next \ prev.next = new.next newNode.deeps[i] = cache[i].deeps[i] cache[i].deeps[i] = newNode
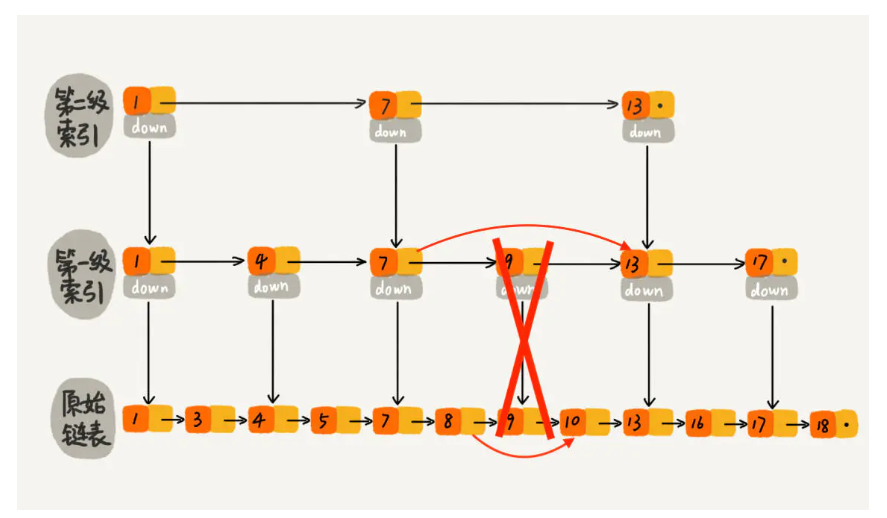
defdelete(self, val): ''' 删除时, 要将每个索引层中对应的节点都删掉 ''' # cache用来缓存对应索引层中小于插入值的最大节点 cache = [None] * self._high cur = self._head # 缓存每一个索引层定位小于插入值的节点 for i in range(self._high - 1, -1, -1): while cur.deeps[i] and cur.deeps[i].data < val: cur = cur.deeps[i] cache[i] = cur # 如果给定的值存在, 更新索引层中对应的节点 if cur.deeps[0] and cur.deeps[0].data == val: for i in range(self._high): if cache[i].deeps[i] and cache[i].deeps[i].data == val: cache[i].deeps[i] = cache[i].deeps[i].deeps[i]
defrandomLevel(self, p=0.25): ''' #define ZSKIPLIST_P 0.25 /* Skiplist P = 1/4 */ https://github.com/antirez/redis/blob/unstable/src/t_zset.c ''' high = 1 for _ in range(self.__MAX_LEVEL - 1): if random.random() < p: high += 1 return high
def__repr__(self): vals = [] p = self._head while p.deeps[0]: vals.append(str(p.deeps[0].data)) p = p.deeps[0] return'->'.join(vals)
if __name__ == '__main__': sl = SkipList() for i in range(100): sl.insert(i) print(sl) p = sl.find(7) print(p.data) sl.delete(37) print(sl) sl.delete(37.5) print(sl)