学习自极客时间的《数据结构与算法之美》 作者:王争
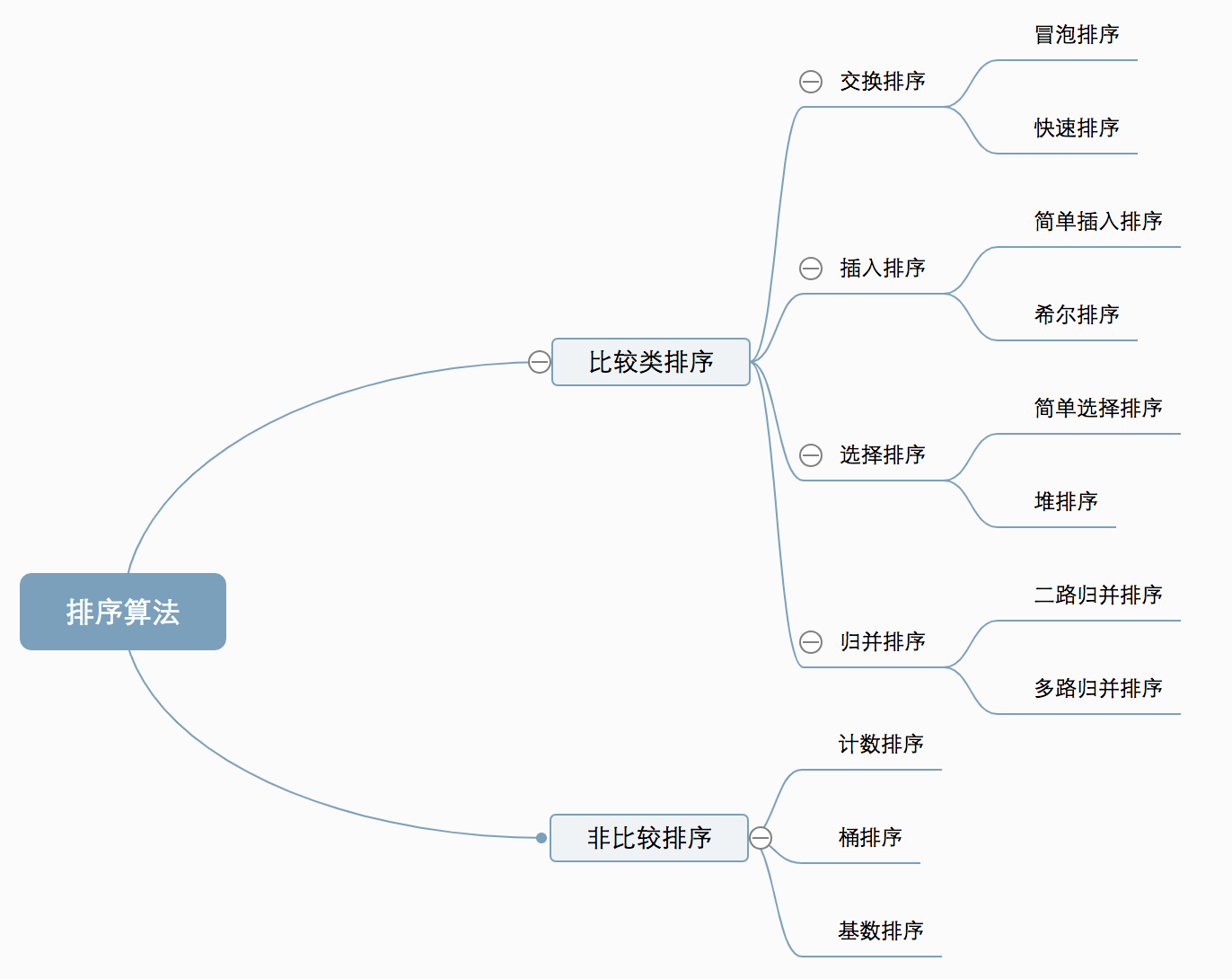
1. 桶排序(Bucket sort)
桶排序,顾名思义,会用到“桶”,核心思想是将要排序的数据分到几个有序的桶里,每个桶里的数据再单独进行排序。桶内排完序之后,再把每个桶里的数据按照顺序依次取出,组成的序列就是有序的了。

1 | def bucketSort(nums): |
桶排序的时间复杂度
如果要排序的数据有 n 个,我们把它们均匀地划分到 m 个桶内,每个桶里就有 k=n/m 个元素。每个桶内部使用快速排序,时间复杂度为 O(k * logk)。m 个桶排序的时间复杂度就是 O(m * k * logk),因为 k=n/m,所以整个桶排序的时间复杂度就是 O(n*log(n/m))。当桶的个数 m 接近数据个数 n 时,log(n/m) 就是一个非常小的常量,这个时候桶排序的时间复杂度接近 O(n)。
桶排序的缺点
桶排序对要排序数据的要求是非常苛刻的。
- 首先,要排序的数据需要很容易就能划分成 m 个桶,并且,桶与桶之间有着天然的大小顺序。这样每个桶内的数据都排序完之后,桶与桶之间的数据不需要再进行排序。
- 其次,数据在各个桶之间的分布是比较均匀的。如果数据经过桶的划分之后,有些桶里的数据非常多,有些非常少,很不平均,那桶内数据排序的时间复杂度就不是常量级了。在极端情况下,如果数据都被划分到一个桶里,那就退化为 O(nlogn) 的排序算法了。
桶排序比较适合用在外部排序中。所谓的外部排序就是数据存储在外部磁盘中,数据量比较大,内存有限,无法将数据全部加载到内存中。
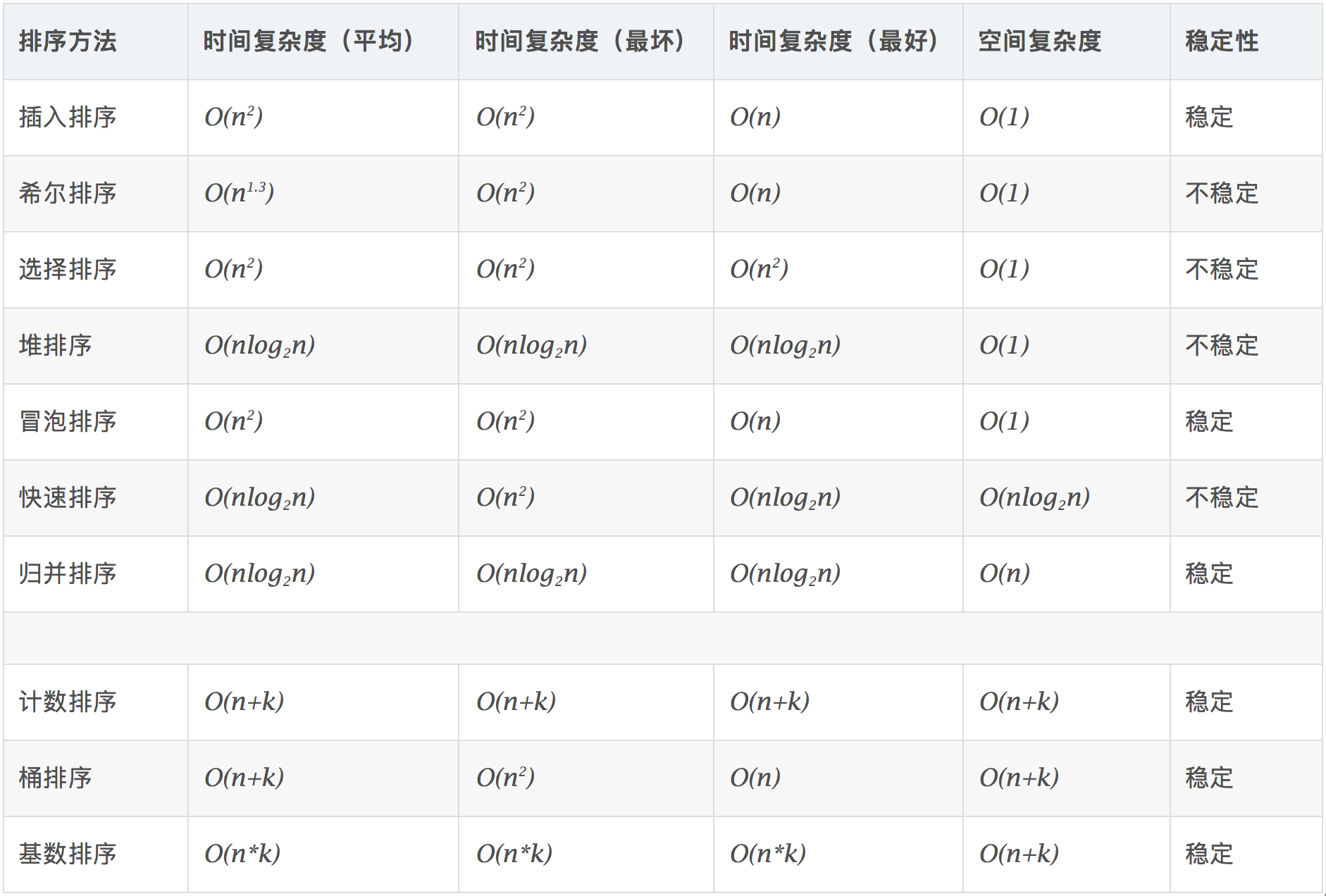
2. 计数排序(Counting sort)
计数排序其实是桶排序的一种特殊情况。当要排序的 n 个数据,所处的范围并不大的时候,比如最大值是 k,我们就可以把数据划分成 k 个桶。每个桶内的数据值都是相同的,省掉了桶内排序的时间。
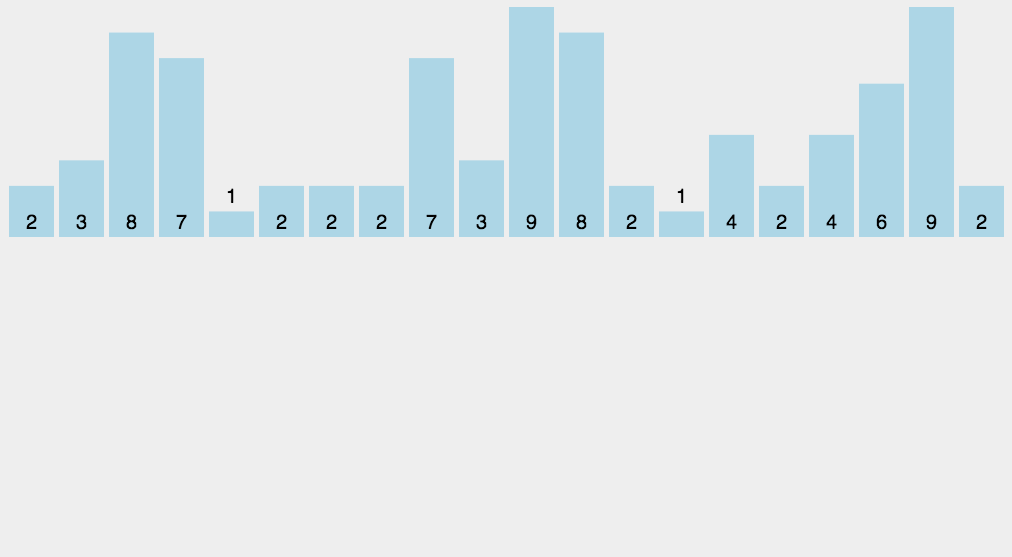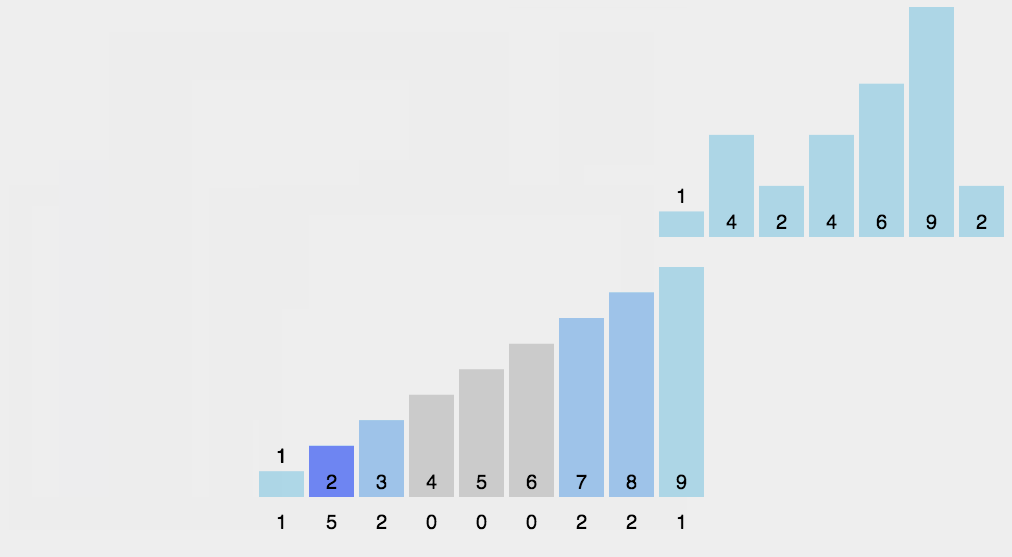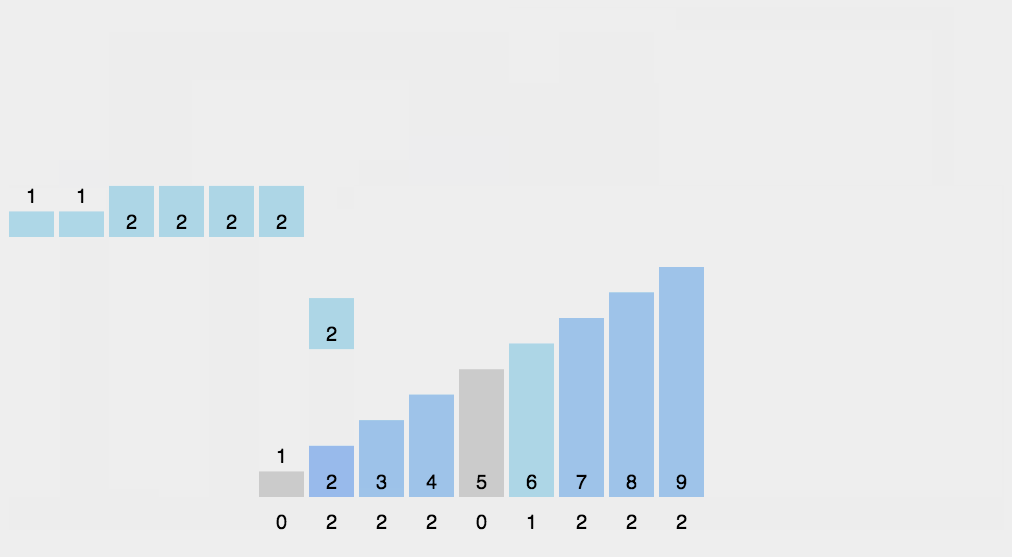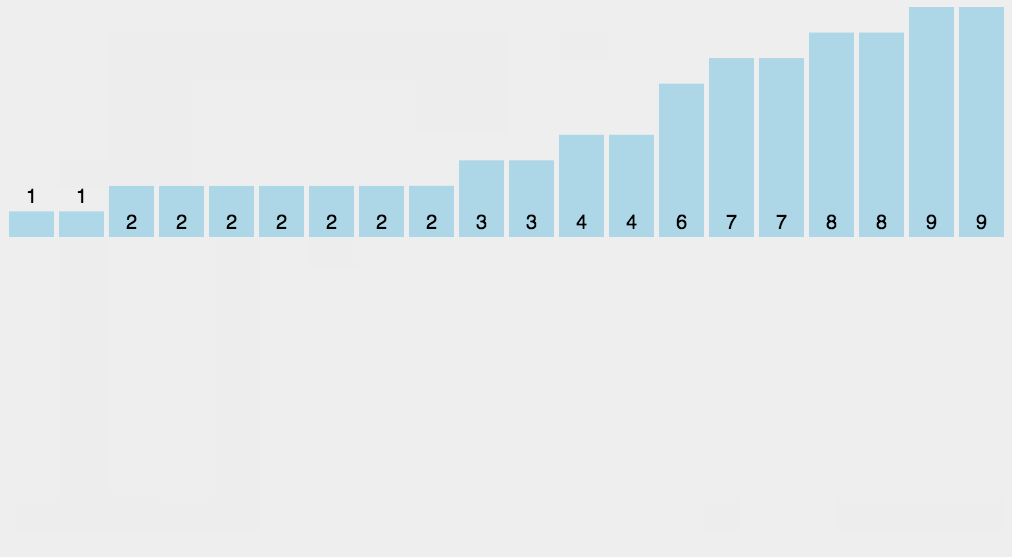
1 | def countingSort(arr): |
计数排序的优化
如何快速计算出,每个数在有序数组中对应的存储位置呢?这个处理方法非常巧妙,很不容易想到。
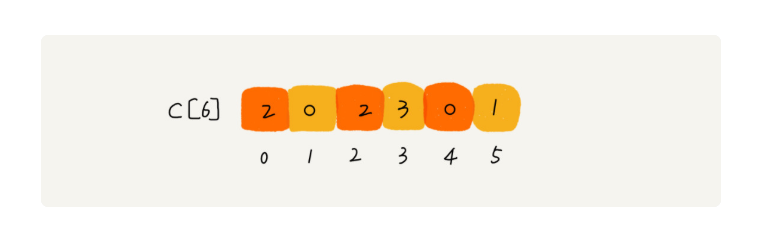
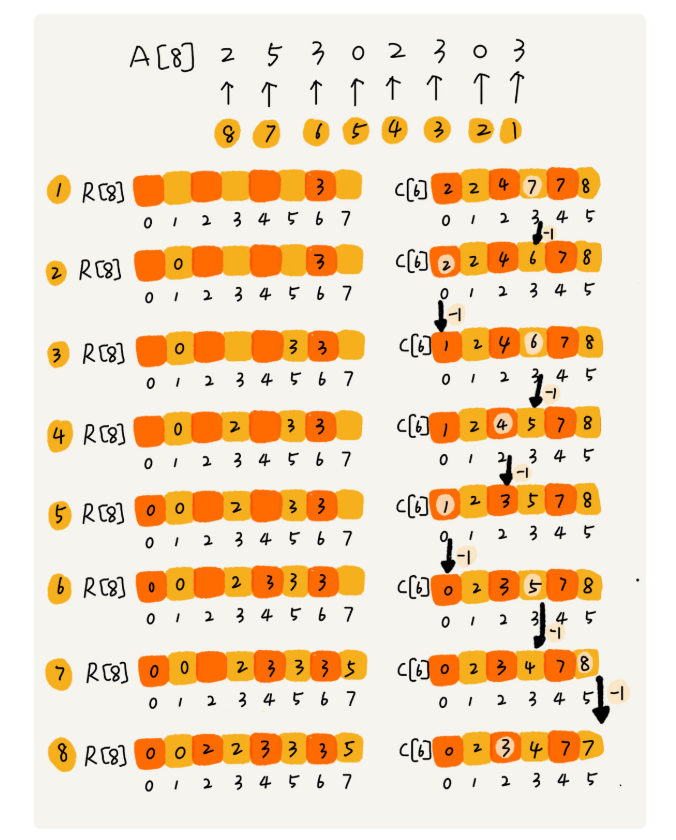
假设只有 8 个数字,分数在 0 到 5 分之间。这 8 个数字的值我们放在一个数组 A[8]中,它们分别是:2,5,3,0,2,3,0,3。
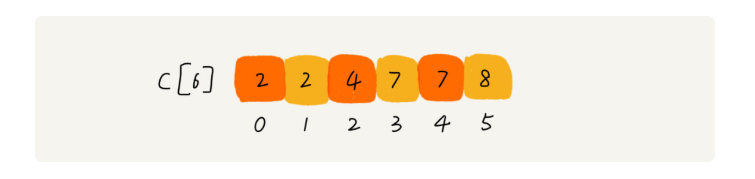
我们使用大小为 6 的数组 C[6]表示桶,其中下标对应分数。不过,C[6]内存储的并不是考生,而是对应的考生个数。像我刚刚举的那个例子,我们只需要遍历一遍考生分数,就可以得到 C[6]的值。
分数为 3 分的考生有 3 个,小于 3 分的考生有 4 个,所以,成绩为 3 分的考生在排序之后的有序数组 R[8]中,会保存下标 4,5,6 的位置。
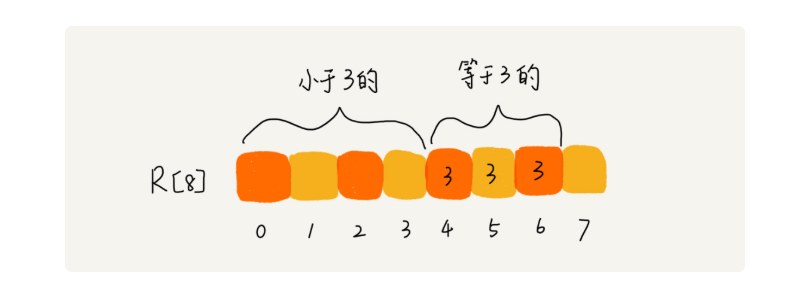
我们对 C[6]数组顺序求和,C[6]存储的数据就变成了下面这样子。C[k]里存储小于等于分数 k 的考生个数。
从后到前依次扫描数组 A。比如,当扫描到 3 时,我们可以从数组 C 中取出下标为 3 的值 7,也就是说,到目前为止,包括自己在内,分数小于等于 3 的考生有 7 个,也就是说 3 是数组 R 中的第 7 个元素(也就是数组 R 中下标为 6 的位置)。当 3 放入到数组 R 中后,小于等于 3 的元素就只剩下了 6 个了,所以相应的 C[3]要减 1,变成 6。
1 | from typing import List |
计数排序只能用在数据范围不大的场景中,如果数据范围 k 比要排序的数据 n 大很多,就不适合用计数排序了。而且,计数排序只能给非负整数排序,如果要排序的数据是其他类型的,要将其在不改变相对大小的情况下,转化为非负整数。
3. 基数排序(Radix sort)
基数排序是按照低位先排序,然后收集;再按照高位排序,然后再收集;依次类推,直到最高位。有时候有些属性是有优先级顺序的,先按低优先级排序,再按高优先级排序。最后的次序就是高优先级高的在前,高优先级相同的低优先级高的在前。

1 | def radix_sort(res, d): |
基数排序对要排序的数据是有要求的,需要可以分割出独立的“位”来比较,而且位之间有递进的关系,如果 a 数据的高位比 b 数据大,那剩下的低位就不用比较了。除此之外,每一位的数据范围不能太大,要可以用线性排序算法来排序,否则,基数排序的时间复杂度就无法做到 O(n) 了。解答开篇
总结