单词的压缩编码 力扣第820题:https://leetcode-cn.com/problems/short-encoding-of-words/
给定一个单词列表,我们将这个列表编码成一个索引字符串 S 与一个索引列表 A。
例如,如果这个列表是 [“time”, “me”, “bell”],我们就可以将其表示为 S = “time#bell#” 和 indexes = [0, 2, 5]。
对于每一个索引,我们可以通过从字符串 S 中索引的位置开始读取字符串,直到 “#” 结束,来恢复我们之前的单词列表。
那么成功对给定单词列表进行编码的最小字符串长度是多少呢?
示例:
输入: words = [“time”, “me”, “bell”]
1. 字符串翻转 + 排序 首先读懂题意,如果某个单词为另一个单词的后缀,则该单词用另一个加上#表示。我首先想到的就是把后缀相同的单词排在一起,但是排序是从前缀开始的,所以需要翻转。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class Solution : def minimumLengthEncoding (self, words: List[str]) -> int: if not words: return 0 words.sort(key = lambda x: x[::-1 ],reverse=True ) lenght = 0 word_compare = '' for i in range(len(words)): if word_compare.endswith(words[i]): continue lenght += len(words[i]) + 1 word_compare = words[i] return lenght
复杂度分析 时间复杂度: 将字符串排序的时间复杂度为 O(nlogn), 然后只需遍历一次列表就能完成压缩,时间复杂度为 O(n),所以总的时间复杂度为 O(nlogn)。
空间复杂度: 用了两个变量,所以空间复杂度为O(1)。
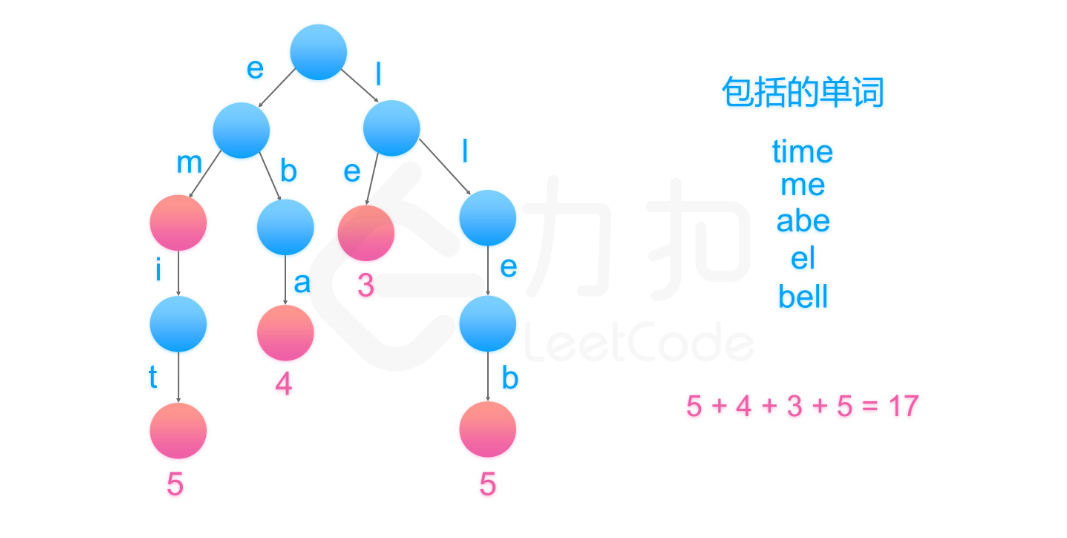
2. 字典树/Trie树 去找到是否不同的单词具有相同的后缀,我们可以将其反序之后插入字典树中。例如,我们有 “time” 和 “me”,可以将 “emit” 和 “em” 插入字典树中。
1 2 3 4 5 6 7 8 9 10 11 12 class Solution : def minimumLengthEncoding (self, words: List[str]) -> int: words = list(set(words)) Trie = lambda : collections.defaultdict(Trie) trie = Trie() nodes = [reduce(dict.__getitem__, word[::-1 ], trie) for word in words] print(words)s return sum(len(word) + 1 for i, word in enumerate(words) if len(nodes[i]) == 0 )
参考至力扣题解:https://leetcode-cn.com/problems/short-encoding-of-words/solution/dan-ci-de-ya-suo-bian-ma-by-leetcode-solution/