
学习自极客时间的《数据结构与算法之美》 作者:王争
栈
一. 什么是栈?
了解枪的弹夹的人应该很清楚,弹夹就是一种栈,我们将子弹压入弹夹中,最后压入的那颗子弹,总是最先发射出去。后进者先出,先进者后出,这就是典型的“栈”结构。
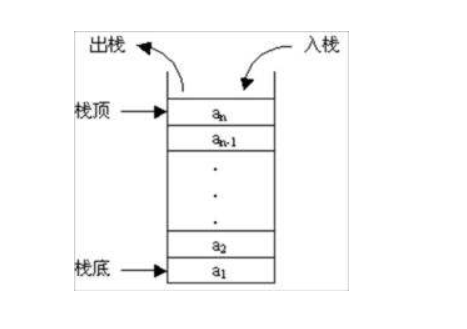
从栈的操作特性上来看,栈是一种“操作受限”的线性表,只允许在一端插入和删除数据。
事实上,从功能上来说,数组或链表确实可以替代栈,但你要知道,特定的数据结构是对特定场景的抽象,而且,数组或链表暴露了太多的操作接口,操作上的确灵活自由,但使用时就比较不可控,自然也就更容易出错。
二. 如何实现一个“栈”?
栈既可以用数组来实现,也可以用链表来实现。用数组实现的栈,我们叫作顺序栈,用链表实现的栈,我们叫作链式栈。
1、顺序栈的实现
这里因为python中没有数组这一数据结构,所以展示java的代码:
1 |
|
2、链式栈的实现
- 首先需要创建一个节点的类
1 | class Node: |
- 然后入栈,首先初始化栈为 None, 然后每一次入栈都更新栈顶元素。
1 | class LinkedStack: |
- 出栈,首先要判断链表是否为空,若不为空,则弹出栈顶元素,然后栈顶元素的下一元素变为栈顶元素
1 | def pop(self) -> Optional[int]: |
不管是顺序栈还是链式栈,我们存储数据只需要一个大小为 n 的数组就够了。在入栈和出栈过程中,只需要一两个临时变量存储空间,所以空间复杂度是 O(1)。
注意,这里存储数据需要一个大小为 n 的数组,并不是说空间复杂度就是 O(n)。因为,这 n 个空间是必须的,无法省掉。所以我们说空间复杂度的时候,是指除了原本的数据存储空间外,算法运行还需要额外的存储空间。
3、 支持动态扩容的顺序栈
基于数组实现的栈,是一个固定大小的栈,也就是说,在初始化栈时需要事先指定栈的大小。当栈满之后,就无法再往栈里添加数据了。尽管链式栈的大小不受限,但要存储 next 指针,内存消耗相对较多。
如果要实现一个支持动态扩容的栈,我们只需要底层依赖一个支持动态扩容的数组就可以了。当栈满了之后,我们就申请一个更大的数组,将原来的数据搬移到新数组中。
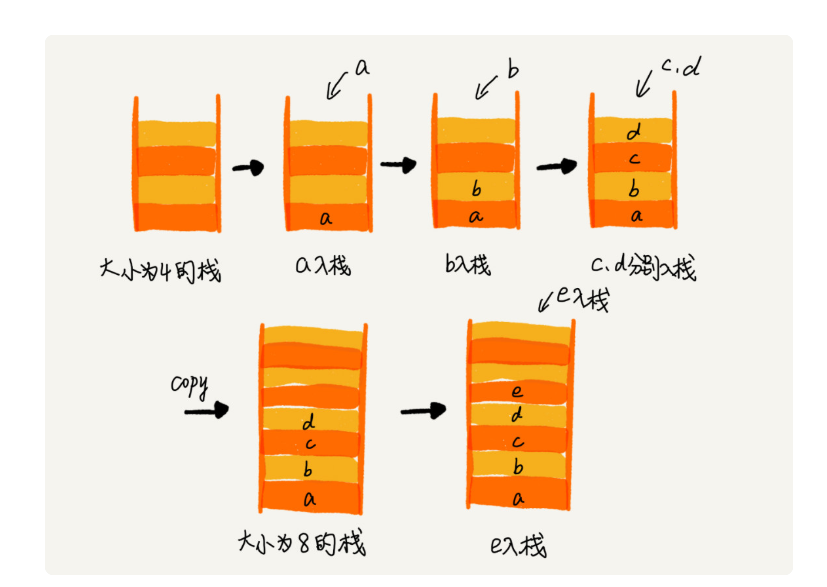
如果当前栈大小为 K,并且已满,当再有新的数据要入栈时,就需要重新申请 2 倍大小的内存,并且做 K 个数据的搬移操作,然后再入栈。但是,接下来的 K-1 次入栈操作,我们都不需要再重新申请内存和搬移数据,所以这 K-1 次入栈操作都只需要一个 simple-push 操作就可以完成。
这 K 次入栈操作,总共涉及了 K 个数据的搬移,以及 K 次 simple-push 操作。将 K 个数据搬移均摊到 K 次入栈操作,那每个入栈操作只需要一个数据搬移和一个 simple-push 操作。以此类推,入栈操作的均摊时间复杂度就为 O(1)。
栈的运用
1. 栈在函数调用中的应用
操作系统给每个线程分配了一块独立的内存空间,这块内存被组织成“栈”这种结构, 用来存储函数调用时的临时变量。每进入一个函数,就会将临时变量作为一个栈帧入栈,当被调用函数执行完成,返回之后,将这个函数对应的栈帧出栈。
1 |
|
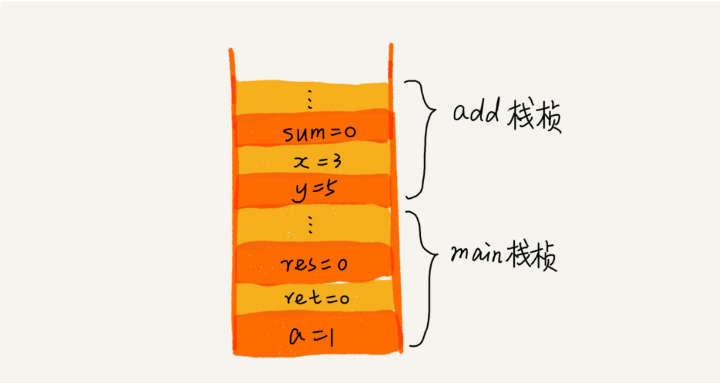
- 首先main函数进栈,因为main方法调用了add方法,所以add函数也进栈。
- 当add方法执行完后add方法出栈,返回值,main继续执行,当main执行完成后main也出栈。所以他们的出栈顺序是 add –> main。
函数的递归也离不开栈,递归的底层实现就是利用栈的数据结构。
2. 栈在表达式求值中的应用
当机器对一个表达式求值的时候,编译器就是通过两个栈来实现的。其中一个保存操作数的栈,另一个是保存运算符的栈。我们从左向右遍历表达式,当遇到数字,我们就直接压入操作数栈;当遇到运算符,就与运算符栈的栈顶元素进行比较。如果比运算符栈顶元素的优先级高,就将当前运算符压入栈;如果比运算符栈顶元素的优先级低或者相同,从运算符栈中取栈顶运算符,从操作数栈的栈顶取 2 个操作数,然后进行计算,再把计算完的结果压入操作数栈,继续比较。
3. 栈在括号匹配中的应用
们用栈来保存未匹配的左括号,从左到右依次扫描字符串。当扫描到左括号时,则将其压入栈中;当扫描到右括号时,从栈顶取出一个左括号。如果能够匹配,比如“(”跟“)”匹配,“[”跟“]”匹配,“{”跟“}”匹配,则继续扫描剩下的字符串。如果扫描的过程中,遇到不能配对的右括号,或者栈中没有数据,则说明为非法格式。