
学习自极客时间《趣谈网络协议》 作者:刘超
1. UDP协议
1.1 TCP 和 UDP的区别
- TCP 是面向连接的,UDP 是面向无连接的。
所谓的建立连接,是为了在客户端和服务端维护连接,而建立一定的数据结构来维护双方交互的状态,用这样的数据结构来保证所谓的面向连接的特性。
TCP提供可靠交付,通过 TCP 连接传输的数据,无差错、不丢失、不重复、并且按序到达。UDP 继承了 IP 包的特性,不保证不丢失,不保证按顺序到达。
TCP是面向字节流的,而 UDP 继承了 IP 的特性,基于数据报的,一个一个地发,一个一个地收。
TCP 是可以有拥塞控制的。它意识到包丢弃了或者网络的环境不好了,就会根据情况调整自己的行为,看看是不是发快了,要不要发慢点。UDP 就不会,应用让我发,我就发,管它洪水滔天。
TCP 其实是一个有状态服务,精确地记着哪个包发送了没有,接收到没有,发送到哪个了,应该接收哪个了,错一点儿都不行。而 UDP 则是无状态服务。通俗地说是没脑子的,天真无邪的,发出去就发出去了。
1.2 UDP 包头是什么样的?
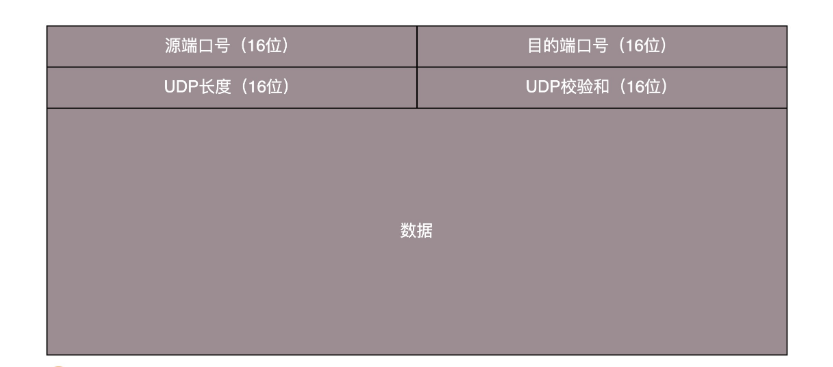
无论应用程序写的使用 TCP 传数据,还是 UDP 传数据,都要监听一个端口,根据端口号,将数据交给相应的应用程序。
1.3 UDP 的三大使用场景
需要资源少,在网络情况比较好的内网,或者对于丢包不敏感的应用。DHCP 就是基于 UDP 协议的。一般的获取 IP 地址都是内网请求,而且一次获取不到 IP 又没事,过一会儿还有机会。PXE 可以在启动的时候自动安装操作系统,操作系统镜像的下载使用的 TFTP,这个也是基于 UDP 协议的。在还没有操作系统的时候,客户端拥有的资源很少,不适合维护一个复杂的状态机,而且因为是内网,一般也没啥问题。
不需要一对一沟通,建立连接,而是可以广播的应用。UDP 的不面向连接的功能,可以使得可以承载广播或者多播的协议。DHCP 就是一种广播的形式,就是基于 UDP 协议的。
需要处理速度快,时延低,可以容忍少数丢包,但是要求即便网络拥塞,也毫不退缩,一往无前的时候。
1.4 基于 UDP 的例子
网页或者 APP 的访问
原来访问网页和手机 APP 都是基于 HTTP 协议的。HTTP 协议是基于 TCP 的,建立连接都需要多次交互,对于时延比较大的目前主流的移动互联网来讲,建立一次连接需要的时间会比较长,然而既然是移动中,TCP 可能还会断了重连,也是很耗时的。而且目前的 HTTP 协议,往往采取多个数据通道共享一个连接的情况,这样本来为了加快传输速度,但是 TCP 的严格顺序策略使得哪怕共享通道,前一个不来,后一个和前一个即便没关系,也要等着,时延也会加大。流媒体的协议
直播协议多使用 RTMP,而这个 RTMP 协议也是基于 TCP 的。TCP 的严格顺序传输要保证前一个收到了,下一个才能确认,如果前一个收不到,下一个就算包已经收到了,在缓存里面,也需要等着。对于直播来讲,这显然是不合适的,因为老的视频帧丢了其实也就丢了,就算再传过来用户也不在意了,他们要看新的了,如果老是没来就等着,卡顿了,新的也看不了,那就会丢失客户,所以直播,实时性比较比较重要,宁可丢包,也不要卡顿的。还有就是当网络不好的时候,TCP 协议会主动降低发送速度,这对本来当时就卡的看视频来讲是要命的,应该应用层马上重传,而不是主动让步。因而,很多直播应用,都基于 UDP 实现了自己的视频传输协议。实时游戏
游戏对实时要求较为严格的情况下,采用自定义的可靠 UDP 协议,自定义重传策略,能够把丢包产生的延迟降到最低,尽量减少网络问题对游戏性造成的影响。IoT 物联网
一方面,物联网领域终端资源少,很可能只是个内存非常小的嵌入式系统,而维护 TCP 协议代价太大;另一方面,物联网对实时性要求也很高,而 TCP 还是因为上面的那些原因导致时延大。Google 旗下的 Nest 建立 Thread Group,推出了物联网通信协议 Thread,就是基于 UDP 协议的。移动通信领域
在 4G 网络里,移动流量上网的数据面对的协议 GTP-U 是基于 UDP 的。因为移动网络协议比较复杂,而 GTP 协议本身就包含复杂的手机上线下线的通信协议。如果基于 TCP,TCP 的机制就显得非常多余。
1.5 问题思考
都说 TCP 是面向连接的,在计算机看来,怎么样才算一个连接呢?
- TCP/UDP建立连接的本质就是在客户端和服务端各自维护一定的数据结构(一种状态机),来记录和维护这个“连接”的状态 。并不是真的会在这两个端之间有一条类似“网络专线”这么一个东西。
- 在IP层,网络情况该不稳定还是不稳定,数据传输走的是什么路径上层是控制不了的,TCP能做的只能是做更多判断,更多重试,更多拥塞控制之类的东西。
2. TCP协议(上)
2.1 TCP 包头格式
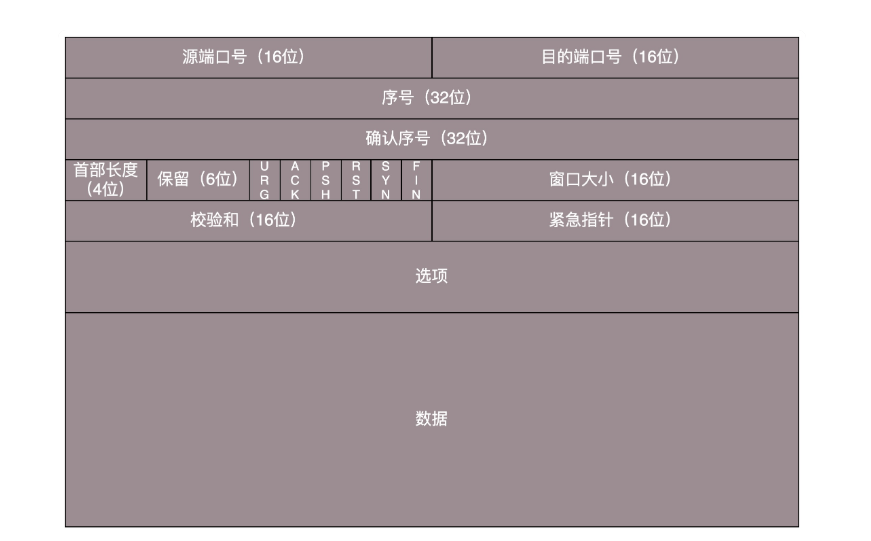
- 源端口和目的端口: 两个应用程序通讯少不了端口
- *序号和确认序号: *编号是为了解决乱序问题。发出去的包应该有确认,如果没有收到就应该重新发送,直到送达。确认序号可以解决不丢包的问题。
- *状态位: *SYN 是发起一个连接,ACK 是回复,RST 是重新连接,FIN 是结束连接等。TCP 是面向连接的,因而双方要维护连接的状态,这些带状态位的包的发送,会引起双方的状态变更。
- *窗口大小: *TCP 要做流量控制,通信双方各声明一个窗口,标识自己当前能够的处理能力,别发送的太快,也别发的太慢。除了做流量控制以外,TCP 还会做拥塞控制。
2.2 TCP三次握手
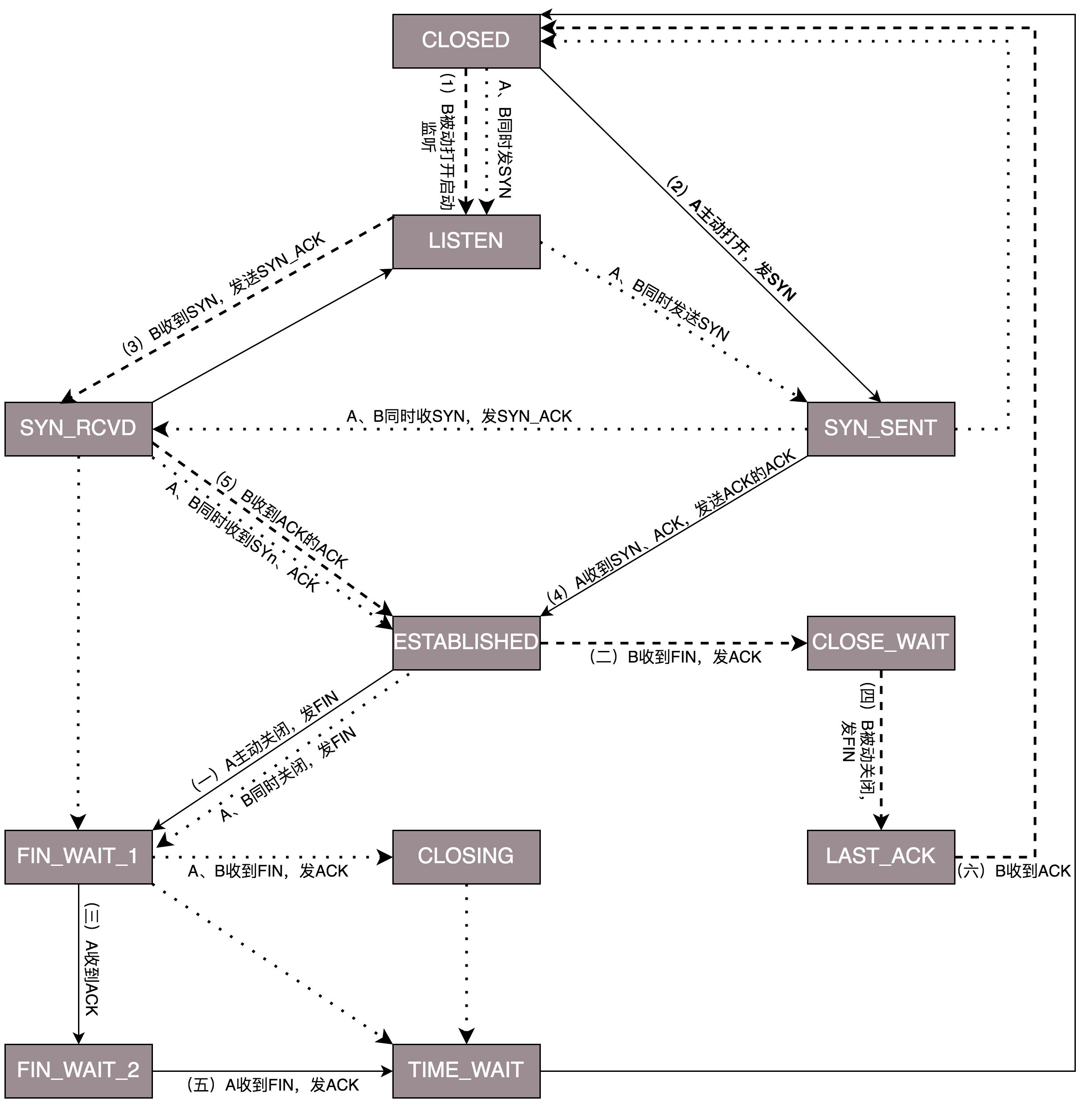
- 一开始,客户端和服务端都处于 CLOSED 状态。先是服务端主动监听某个端口,处于 LISTEN 状态。然后客户端主动发起连接 SYN,之后处于 SYN-SENT 状态。
- 服务端收到发起的连接,返回 SYN,并且 ACK 客户端的 SYN,之后处于 SYN-RCVD 状态。
- 客户端收到服务端发送的 SYN 和 ACK 之后,发送 ACK 的 ACK,之后处于 ESTABLISHED 状态,因为它一发一收成功了。服务端收到 ACK 的 ACK 之后,处于 ESTABLISHED 状态,因为它也一发一收了。
为了维护这个连接,双方都要维护一个状态机,在连接建立的过程中,双方的状态变化时序图就像这样。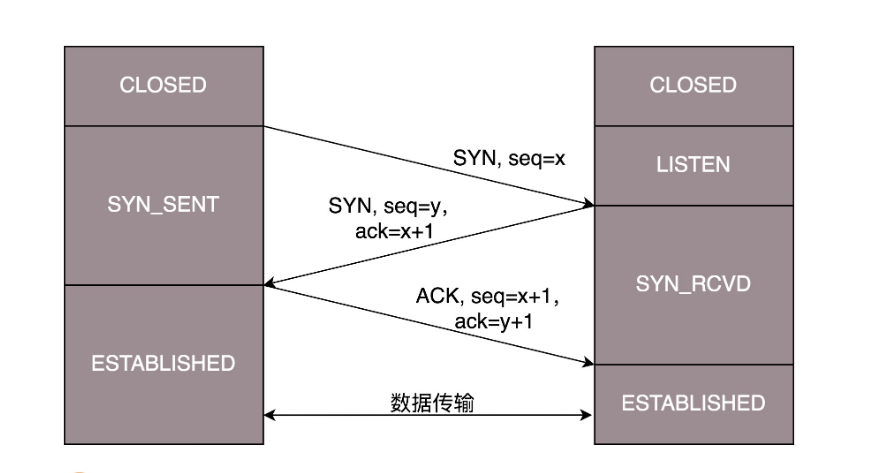
三次握手除了双方建立连接外,主要还是为了沟通一件事情,就是 TCP 包的序号的问题。每个连接都要有不同的序号。这个序号的起始序号是随着时间变化的,可以看成一个 32 位的计数器,每 4ms 加一,如果计算一下,如果到重复,需要 4 个多小时,那个绕路的包早就死翘翘了,因为我们都知道 IP 包头里面有个 TTL,也即生存时间。
为什么要三次,而不是两次?按说两个人打招呼,一来一回就可以了啊?为了可靠,为什么不是四次?
假设A要与B通讯,当A发起第一个请求是,可能请求到达不了B,或者B没有响应,这时候A就会选择继续重发,终于B收到了A的消息,知道A想要连接,但是A还不知道,可能还会继续重发。
B 收到了请求包,就知道了 A 的存在,并且知道 A 要和它建立连接。如果 B 不乐意建立连接,则 A 会重试一阵后放弃,连接建立失败,没有问题;如果 B 是乐意建立连接的,则会发送应答包给 A。当然对于 B 来说,这个应答包也是一入网络深似海,不知道能不能到达 A。这个时候 B 自然不能认为连接是建立好了,因为应答包仍然会丢,会绕弯路,或者 A 已经挂了都有可能。
而且这个时候 B 还能碰到一个诡异的现象就是,A 和 B 原来建立了连接,做了简单通信后,结束了连接。还记得吗?A 建立连接的时候,请求包重复发了几次,有的请求包绕了一大圈又回来了,B 会认为这也是一个正常的的请求的话,因此建立了连接,可以想象,这个连接不会进行下去,也没有个终结的时候,纯属单相思了。因而两次握手肯定不行。
当然 A 发给 B 的应答之应答也会丢,也会绕路,甚至 B 挂了。按理来说,还应该有个应答之应答之应答,这样下去就没底了。所以四次握手是可以的,四十次都可以,关键四百次也不能保证就真的可靠了。只要双方的消息都有去有回,就基本可以了。
2.3 TCP四次挥手
- 断开的时候,客户端首先发起FIN请求,接着进入FIN_WAIT_1 的状态。服务器接收到客户端的FIN的请求后,就ACK客户端的请求,然后进入CLOSE_WAIT 的状态。
- 客户端收到服务器的ACK后,便进入FIN_WAIT_2 的状态,如果这个时候 服务器 直接跑路,则客户端将永远在这个状态。TCP 协议里面并没有对这个状态的处理,但是 Linux 有,可以调整 tcp_fin_timeout 这个参数,设置一个超时时间。
- 服务器也想断开连接,便向客户端发送FIN,表示要结束连接。
- 客户端收到服务器发来的FIN,也向服务器发送一个ACK,确认收到了服务器的请求,便从 FIN_WAIT_2 状态结束。为了确保服务器能够收到这个ACK,TCP 协议要求客户端最后等待一段时间 TIME_WAIT,这个时间要足够长,长到如果服务器没收到 ACK 的话,服务器会重发FIN,客户端收到后也会重新发一个 ACK 并且足够时间到达服务器。而且如果客户端没有等待足够的时间,端口就直接空出来了,但是服务器不知道,服务器原来发过的很多包很可能还在路上,如果客户端的端口被一个新的应用占用了,这个新的应用会收到上个连接中服务器发过来的包。等待的时间设为 2MSL,MSL 是 Maximum Segment Lifetime,报文最大生存时间,它是任何报文在网络上存在的最长时间,超过这个时间报文将被丢弃。
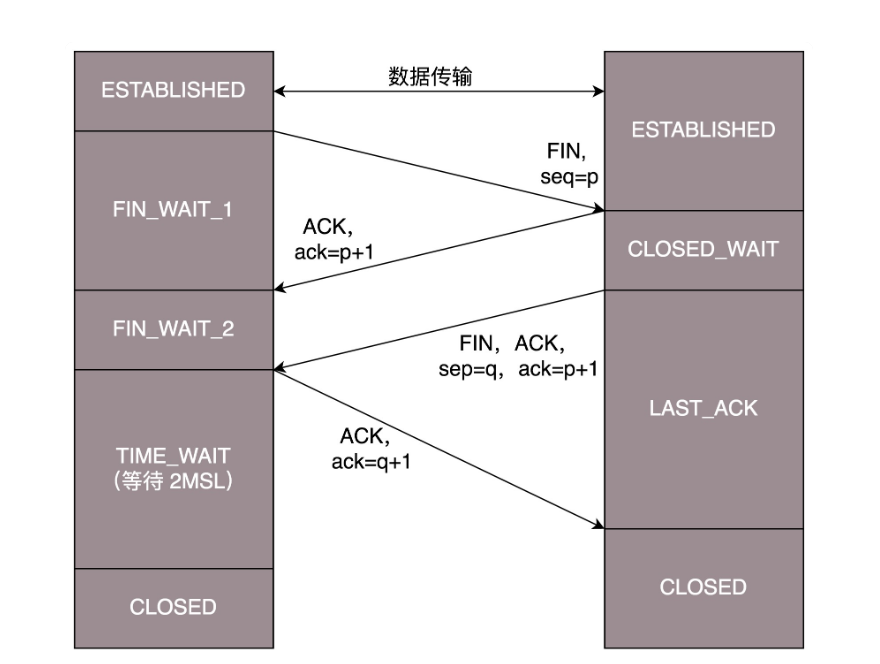
2.4 TCP 状态机
2.5 问题思考
- TCP 的连接有这么多的状态,如何在系统中查看某个连接的状态?
- netstat可以在系统中查看某个连接的状态。
2.如何避免TCP的TIME_WAIT状态(高并发)?
首先服务器可以设置SO_REUSEADDR套接字选项来通知内核,如果端口忙,但TCP连接位于TIME_WAIT状态时可以重用端口。在一个非常有用的场景就是,如果你的服务器程序停止后想立即重启,而新的套接字依旧希望使用同一端口,此时SO_REUSEADDR选项就可以避免TIME_WAIT状态。
如何避免TCP的TIME_WAIT状态(高并发)
- 服务器遭到SYN攻击怎么办?如何防御SYN攻击?
3. TCP 协议(下)
3.1 如何实现一个靠谱的协议?
为了保证顺序性,每一个包都有一个 ID。在建立连接的时候,会商定起始的 ID 是什么,然后按照 ID 一个个发送。为了保证不丢包,对于发送的包都要进行应答,但是这个应答也不是一个一个来的,而是会应答某个之前的 ID,表示都收到了,这种模式称为累计确认或者累计应答(cumulative acknowledgment)。
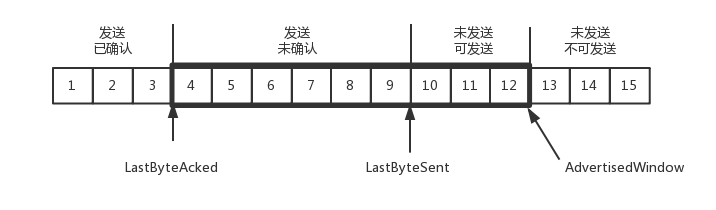
为了记录所有发送的包和接收的包,TCP 也需要发送端和接收端分别都有缓存来保存这些记录。发送端的缓存里是按照包的 ID 一个个排列,根据处理的情况分成四个部分。
- 第一部分, 发送并确认的。
- 第二部分, 发送了尚未确认的。
- 第三部分, 没有发送,但是已经等待发送的。
- 第四部分, 没有发送,并且暂时还不会发送的。
区分第三和第四部分是因为要流量控制,把握分寸,根据窗口的工作量先评估一下,多了就加,少了就减。
在 TCP 里,接收端会给发送端报一个窗口的大小,叫 Advertised window。这个窗口的大小应该等于上面的第二部分加上第三部分。超过这个窗口的,接收端做不过来,就不能发送了。
发送端需要保持下面的数据结构:
接收方的数据结构如下:
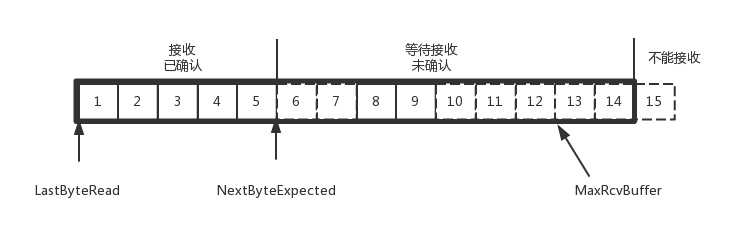
AdvertisedWindow=MaxRcvBuffer-((NextByteExpected-1)-LastByteRead)。
其中第二部分里面,由于受到的包可能不是顺序的,会出现空挡,只有和第一部分连续的,可以马上进行回复,中间空着的部分需要等待,哪怕后面的已经来了。
3.2 顺序问题与丢包问题
发送方和接收方可能会出现以下情况:
- 接收方接受到了包并发送了相应的ACK,但是可能在路上丢失了.
- 接收方接受了包但是这个包的前一个包没有接收到,出现了乱序,所以只能缓存着不能ACK
顺序问题和丢包问题都有可能发生,所以我们先来看确认与重发的机制。
- 一种方法就是超时重试,也即对每一个发送了,但是没有 ACK 的包,都有设一个定时器,超过了一定的时间,就重新尝试。
估计往返时间,需要 TCP 通过采样 RTT 的时间,然后进行加权平均,算出一个值,而且这个值还是要不断变化的,因为网络状况不断的变化。除了采样 RTT,还要采样 RTT 的波动范围,计算出一个估计的超时时间。由于重传时间是不断变化的,我们称为自适应重传算法。
每当遇到一次超时重传的时候,都会将下一次超时时间间隔设为先前值的两倍。两次超时,就说明网络环境差,不宜频繁反复发送。
有一个可以快速重传的机制,当接收方收到一个序号大于下一个所期望的报文段时,就会检测到数据流中的一个间隔,于是它就会发送冗余的 ACK,仍然 ACK 的是期望接收的报文段。而当客户端收到三个冗余的 ACK 后,就会在定时器过期之前,重传丢失的报文段
- 还有一种方式称为 Selective Acknowledgment (SACK)。这种方式需要在 TCP 头里加一个 SACK 的东西,可以将缓存的地图发送给发送方。例如可以发送 ACK6、SACK8、SACK9,有了地图,发送方一下子就能看出来是 7 丢了。
3.3 流量控制问题
- 当发送方发送包的数量过大,例如将第三部分没有发送但等待发送的包一次性发完,这时候只有当发送方收到接收方发来的ACK,才能继续发送包。
- 如果接收方实在处理的太慢,导致缓存中没有空间了,可以通过确认信息修改窗口的大小,甚至可以设置为 0,则发送方将暂时停止发送。如果接收端还是一直不处理数据,则随着确认的包越来越多,窗口越来越小,直到为 0。
- 发送方会定时发送窗口探测数据包,看是否有机会调整窗口的大小。当接收方比较慢的时候,要防止低能窗口综合征,别空出一个字节来就赶快告诉发送方,然后马上又填满了,可以当窗口太小的时候,不更新窗口,直到达到一定大小,或者缓冲区一半为空,才更新窗口。
3.4 拥塞控制问题
拥塞控制的问题,也是通过窗口的大小来控制的,前面的滑动窗口 rwnd 是怕发送方把接收方缓存塞满,而拥塞窗口 cwnd,是怕把网络塞满。
- 原来发送一个包,从一端到达另一端,假设一共经过四个设备,每个设备处理一个包时间耗费 1s,所以到达另一端需要耗费 4s,如果发送的更加快速,则单位时间内,会有更多的包到达这些中间设备,这些设备还是只能每秒处理一个包的话,多出来的包就会被丢弃,这是我们不想看到的。
- 这个时候,我们可以想其他的办法,例如这个四个设备本来每秒处理一个包,但是我们在这些设备上加缓存,处理不过来的在队列里面排着,这样包就不会丢失,但是缺点是会增加时延,这个缓存的包,4s 肯定到达不了接收端了,如果时延达到一定程度,就会超时重传,也是我们不想看到的。
TCP 的拥塞控制主要来避免两种现象,包丢失和超时重传。一旦出现了这些现象就说明,发送速度太快了,要慢一点。
窗口调整的办法: 慢启动
- 一条 TCP 连接开始,cwnd 设置为一个报文段,一次只能发送一个;当收到这一个确认的时候,cwnd 加一,于是一次能够发送两个;当这两个的确认到来的时候,每个确认 cwnd 加一,两个确认 cwnd 加二,于是一次能够发送四个;当这四个的确认到来的时候,每个确认 cwnd 加一,四个确认 cwnd 加四,于是一次能够发送八个。可以看出这是指数性的增长。
- 有一个值 ssthresh 为 65535 个字节,当超过这个值的时候,就要小心一点了,不能倒这么快了,要慢下来。每收到一个确认后,cwnd 增加 1/cwnd,我们接着上面的过程来,一次发送八个,当八个确认到来的时候,每个确认增加 1/8,八个确认一共 cwnd 增加 1,于是一次能够发送九个,变成了线性增长。但是始终都会溢出。
- 快速重传算法。当接收端发现丢了一个中间包的时候,发送三次前一个包的 ACK,于是发送端就会快速的重传,不必等待超时再重传。TCP 认为这种情况不严重,因为大部分没丢,只丢了一小部分,这时候就将cwnd 减半为 cwnd/2,然后 sshthresh = cwnd,当三个包返回的时候,cwnd = sshthresh + 3,也就是没有一夜回到解放前,而是还在比较高的值,呈线性增长。
但是还是会出现问题;
- 第一个问题是丢包并不代表着通道满了,也可能是管子本来就漏水。例如公网上带宽不满也会丢包,这个时候就认为拥塞了,退缩了,其实是不对的。
- 第二个问题是 TCP 的拥塞控制要等到将中间设备都填充满了,才发生丢包,从而降低速度,这时候已经晚了。其实 TCP 只要填满管道就可以了,不应该接着填,直到连缓存也填满。
为了优化这两个问题,后来有了 TCP BBR 拥塞算法。它企图找到一个平衡点,就是通过不断的加快发送速度,将管道填满,但是不要填满中间设备的缓存,因为这样时延会增加,在这个平衡点可以很好的达到高带宽和低时延的平衡。
3.5 问题思考
TCP 的 BBR 听起来很牛,你知道他是如何达到这个最优点的嘛?
1 设备缓存会导致延时?
假如经过设备的包都不需要进入缓存,那么得到的速度是最快的。进入缓存且等待,等待的时间就是额外的延时。BBR就是为了避免这些问题:
充分利用带宽;降低buffer占用率。
2 降低发送packet的速度,为何反而提速了?
标准TCP拥塞算法是遇到丢包的数据时快速下降发送速度,因为算法假设丢包都是因为过程设备缓存满了。快速下降后重新慢启动,整个过程对于带宽来说是浪费的。通过packet速度-时间的图来看,从积分上看,BBR充分利用带宽时发送效率才是最高的。可以说BBR比标准TCP拥塞算法更正确地处理了数据丢包。对于网络上有一定丢包率的公网,BBR会更加智慧一点。
回顾网络发展过程,带宽的是极大地改进的,而最小延迟会受限与介质传播速度,不会明显减少。BBR可以说是应运而生。
3 BBR如何解决延时?
S1:慢启动开始时,以前期的延迟时间为延迟最小值Tmin。然后监控延迟值是否达到Tmin的n倍,达到这个阀值后,判断带宽已经消耗尽且使用了一定的缓存,进入排空阶段。
S2:指数降低发送速率,直至延迟不再降低。这个过程的原理同S1
S3:协议进入稳定运行状态。交替探测带宽和延迟,且大多数时间下都处于带宽探测阶段。